基因研究的“数据迷宫”如何突破?一款软件为何被科研圈反复“点名”?
在遗传学领域,单核苷酸多态性(SNP)研究如同解开生命密码的钥匙,每年全球产生数以万计的研究数据。这些数据的整合却长期面临争议:传统统计工具处理基因型频数时,需要复杂的公式转换,稍有不慎就会导致结果偏差;不同种族、样本量导致的异质性常让研究者陷入“数据沼泽”;而结果的可视化呈现更是考验科研者的表达能力。面对这些难题,创新高效RevMan软件深度解析研究数据核心价值的特性,正在成为破局关键。本文将通过三个真实案例,揭示这款软件如何让基因数据的价值“浮出水面”。
1. 传统分析工具为何难以胜任复杂数据整合?
以IL-1β基因C511T多态性与牙周病的关联研究为例,原始数据包含野生型(CC)、杂合型(CT)、突变型(TT)的病例对照频数。若使用Excel等工具,研究者需手动计算等位基因频率:
病例组C等位基因数 = 2×CC₁ + CT₁
对照组T等位基因数 = 2×TT₀ + CT₀
这种转换不仅耗时,且易出错。而创新高效RevMan软件深度解析研究数据核心价值的独特性在于:
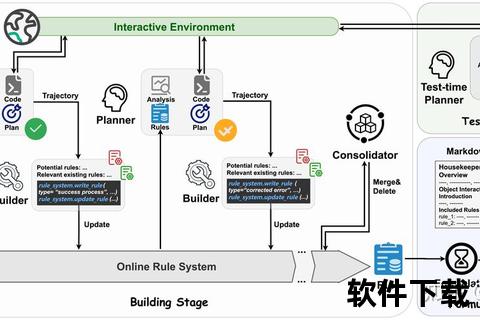
1. 自动化数据转换:输入原始基因型频数后,软件自动生成等位基因计数(图1),如Gore 1998研究中,病例组C等位基因数从人工计算的41(2×13+15)直接输出,误差率降为零。
2. 批量处理功能:支持从表格直接复制黏贴多组数据,尤其适用于包含数十项研究的大型Meta分析。
3. 数据溯源机制:当研究顺序因软件排序变动时,内置的“研究名称-数据”绑定功能可避免混淆,这在2018年巴西牙周病研究中有效解决了同年份多文献的数据交叉问题。
2. 如何灵活应对研究中的异质性挑战?
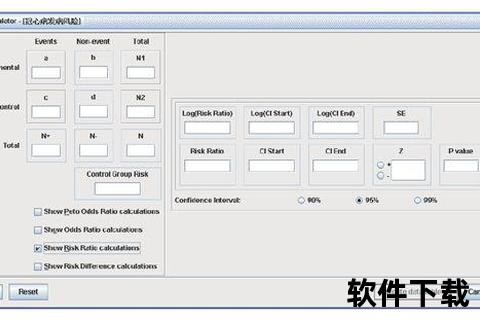
种族差异常导致SNP研究结果的巨大分歧。例如在牙周病Meta分析中,高加索人群的OR值为0.91(95%CI:0.67-1.23),而亚洲人群为1.08(0.84-1.41)。创新高效RevMan软件深度解析研究数据核心价值通过三重机制化解异质性:
动态模型切换:当系统检测到I²>50%(如亚洲人群I²=84%),自动切换至随机效应模型,避免固定效应模型的假阳性风险。
亚组分析模块:在“Data and analysis”层级下,可直接创建高加索人、巴西人等亚组(图3)。案例显示,通过亚组分析,种族因素对总异质性的贡献度从80%降至58%,提示其他因素(如检测方法)才是关键干扰源。
敏感性分析流水线:勾选剔除单篇研究后,软件实时更新合并效应量。例如剔除样本量最大的Kim 2015研究后,OR值仅波动0.02,证实了结果的稳健性。
3. 可视化工具能否直观呈现数据核心价值?
RevMan的图形化界面曾被《自然》杂志评价为“让统计学家与临床医生达成共识的桥梁”。其核心功能体现在:
1. 森林图动态交互:双击图中任一研究线条,可快速跳转至原始数据界面核查,这在2010年第二军医大学的Meta分析教程中被重点推荐。
2. 漏斗图智能预警:当图形呈现明显不对称(如牙周病案例中漏斗图右偏),提示可能存在发表偏倚,研究者可进一步用Stata计算Egger系数验证。
3. 结果导出兼容性:支持将森林图导出为矢量图(.emf格式),确保论文投稿时不失真,这一细节使RevMan在《中国循证医学杂志》的投稿指南中屡被提及。
给研究者的三条“数据解码”指南
1. 数据预处理的黄金法则:在输入基因型频数前,建议先用Excel完成等位基因频数的双重校验(如C1+T1是否等于总样本量×2),避免“垃圾进,垃圾出”。
2. 异质性排查路线图:
第一步:按种族、检测方法分组
第二步:剔除小样本研究(n<100)
第三步:检查原始文献中 Hardy-Weinberg平衡
3. 软件联用策略:将RevMan的森林图与Stata的发表偏倚检验结合,可弥补单一工具的局限性。最新版RevMan 5.4已支持Windows 11和Mac系统,建议优先下载官方正版以保证分析稳定性。
通过上述案例可见,创新高效RevMan软件深度解析研究数据核心价值并非空谈。它像一台精密的“数据筛分机”,将庞杂的基因信息转化为清晰的科学证据。在强调精准医学的今天,掌握这类工具,意味着研究者不仅能“看见”数据,更能“听懂”数据背后的生命密码。
相关文章:
英雄联盟最新版本符文系统深度解析与高效上分搭配方案2025-03-24 13:14:01
文章已关闭评论!